
Standardipoikkeama ja vakiovirhe
esittely
standardi D ilmailu (SD) ja S standardimalliset E rror (SE) ovat näennäisesti samanlaisia termejä; Ne ovat kuitenkin käsitteellisesti niin erilaisia, että niitä käytetään lähes keskenään tilastotieteellisessä kirjallisuudessa. Molempia termejä edeltää yleensä plus-miinusmerkki (+/-), joka osoittaa, että ne määrittelevät symmetrisen arvon tai edustavat arvoja. Väärinkäyttämättä molemmat termit näyttävät mittausarvojen joukosta keskimäärin (keskimäärin).
Mielenkiintoista, että SE: lla ei ole mitään tekemistä standardien, virheiden tai tieteellisten tietojen kanssa.
Yksityiskohtainen tarkastelu SD: n ja SE: n alkuperästä ja selityksistä paljastaa, miksi ammatilliset tilastotieteilijät ja ne, jotka käyttävät sitä kursivoivasti, ovat molempia.
Vakiopoikkeama (SD)
SD on a kuvaileva tilasto, joka kuvaa jakelun leviämistä. Mittana on hyödyllinen, kun tiedot jaetaan normaalisti. Kuitenkin se on vähemmän hyödyllistä, kun tiedot ovat erittäin vinossa tai bimodaalisessa, koska se ei kuvaa hyvin jakautuman muotoa. Tyypillisesti käytämme SD: tä raportoidessamme näytteen ominaisuuksista, koska aiomme kuvata kuinka paljon tiedot vaihtelevat keskimäärin. Muita käyttökelpoisia tilastotietoja tietojen leviämisen kuvaamiseksi ovat kvarttilaajuusalue, 25. ja 75. prosenttiyksikkö ja datanväli.
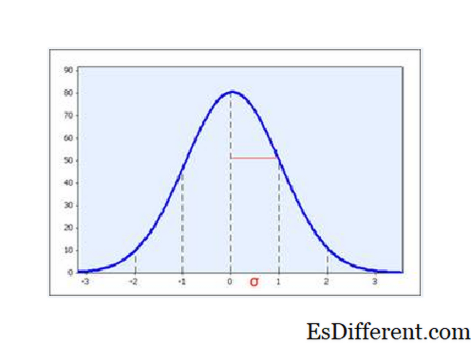
Varianssi on a kuvaileva myös tilastollisesti, ja se määritellään standardipoikkeaman neliöksi. Sitä ei yleensä raportoida tulosten kuvauksessa, mutta se on matemaattisemmin käsiteltävä kaava (esim. Neliöpoikkeamien summa) ja sillä on rooli tilastojen laskennassa.
Esimerkiksi, jos meillä on kaksi tilastoa P & Q tunnetuilla variansseilla var (P) & var (Q) , sitten summan varianssi P + Q on yhtä suuri kuin varianssien summa: var (P) + var (Q) . Nyt on selvää, miksi tilastotieteilijät haluavat puhua varioista.
Mutta standardipoikkeamilla on tärkeä merkitys leviämiselle erityisesti silloin, kun tiedot ovat normaalisti jakautuneita: Keskimääräinen keskiarvo +/- 1 SD voidaan odottaa ottavan 2/3 näytteestä, ja välin keskiarvo + - 2 SD voidaan odottaa ottavan 95% näytteestä.
SD osoittaa, kuinka pitkälle yksittäiset vastaukset kysymykseen vaihtelevat tai "poikkeavat" keskiarvosta. SD kertoo tutkijalle, kuinka levittää vastaukset ovat - ovatko he keskittyneet keskiarvoon tai hajallaan kauas ja laaja? Ovatko kaikki vastaajasi arvioineet tuotteesi keskikokoonsa vai onko jokin hyväksynyt sen ja jotkut hylkäsivät sen?
Harkitse kokeilua, jossa vastaajia pyydetään arvioimaan tuote useilla ominaisuuksilla 5 pisteen asteikolla. Kymmenen vastaajaryhmän keskiarvo ("A" - "J" alla) "hyvälle rahalle" oli 3,2, SD: llä 0,4 ja tuotteen luotettavuuden keskiarvo oli 3,4 ja SD: llä 2,1.
Ensi silmäyksellä (tarkastelemalla vain keinoja) näyttää siltä, että luotettavuus arvioitiin korkeammaksi kuin arvo. Mutta korkeampi SD: n luotettavuus voisi osoittaa (kuten alla olevassa jakelussa näkyy), että vastaukset olivat hyvin polarisoituneita, joissa useimmilla vastaajilla ei ollut luotettavuusongelmia (luokiteltu attribuutiksi "5") mutta pienempi mutta tärkeä vastaajaryhmä luotettavuusongelma ja luokitellut attribuutin "1". Keskitasoa tarkasteltaessa kertoo vain osa tarinaa, mutta useammin kuin ei, tämä on mitä tutkijat keskittyvät. Vastausten jakautuminen on tärkeää tarkastella ja SD antaa arvokasta kuvaavaa toimenpidettä tästä.
| Vastaaja | Hyvä arvo rahaa | Tuotteen luotettavuus |
| 3 | 1 | |
| B | 3 | 1 |
| C | 3 | 1 |
| D | 3 | 1 |
| E | 4 | 5 |
| F | 4 | 5 |
| G | 3 | 5 |
| H | 3 | 5 |
| minä | 3 | 5 |
| J | 3 | 5 |
| Tarkoittaa | 3.2 | 3.4 |
| Std. Dev. | 0.4 | 2.1 |
Ensimmäinen kysely: Vastaajat arvioivat tuotteen 5 pisteen asteikolla
Kaksi hyvin erilaista vastausten jakautumista 5-pisteen asteikkoon voi tuottaa saman keskiarvon. Harkitse seuraava esimerkki, jossa esitetään vastausarvot kahdelle eri luokitukselle.
Ensimmäisessä esimerkissä (Rating "A") SD on nolla, koska kaikki vastaukset olivat täsmälleen keskiarvo. Yksittäiset vastaukset eivät poikenneet lainkaan keskiarvosta.
Arvioinnissa "B", vaikka ryhmän keskiarvo on sama (3,0) kuin ensimmäinen jakautuminen, standardipoikkeama on suurempi. Standardipoikkeama 1.15 osoittaa, että yksittäiset vastaukset keskimäärin * olivat hieman yli 1 pisteen keskiarvosta.
| Vastaaja | Arvosana "A" | Arvosana "B" |
| 3 | 1 | |
| B | 3 | 2 |
| C | 3 | 2 |
| D | 3 | 3 |
| E | 3 | 3 |
| F | 3 | 3 |
| G | 3 | 3 |
| H | 3 | 4 |
| minä | 3 | 4 |
| J | 3 | 5 |
| Tarkoittaa | 3.0 | 3.0 |
| Std. Dev. | 0.00 | 1.15 |
Toinen tutkimus: vastaajat arvioivat tuotteen 5-pistetasolla
Toinen tapa tarkastella SD: ää on piirtäen jakelu histogrammiin vastauksiksi. Alhainen SD: n jakautuminen näyttäisi olevan pitkä kapea muoto, kun taas suuren SD: n olisi osoitettava laajemmalla muodolla.
SD ei yleensä ilmaise "oikeaa tai väärää" tai "parempaa tai pahempaa" - alempi SD ei välttämättä ole toivottavaa. Sitä käytetään pelkästään kuvaavana tilastona. Se kuvaa jakautumista suhteessa keskiarvoon.
T SD: hen liittyvä tekninen vastuuvapauslauseke
SD: n ajattelu "keskimääräiseksi poikkeamaksi" on erinomainen tapa käsitteellisen ymmärryksen merkityksessä. Kuitenkin sitä ei ole tosiasiallisesti laskettu keskimäärin (jos se olisi, me kutsumme sitä "keskimääräiseksi poikkeamaksi"). Sen sijaan se on "standardoitu", hieman monimutkainen menetelmä arvon laskemiseksi neliösumman summan avulla.
Käytännön syistä laskenta ei ole tärkeä. Useimmat tabulointiohjelmat, laskentataulukot tai muut datanhallintatyökalut laskevat SD: n sinulle. Tärkeämpää on ymmärtää, mitä tilastot välittävät.
Standardivirhe
Vakiovirhe on inferential tilasto, jota käytetään vertailemalla näytemateriaaleja (keskiarvoja) populaatioiden välillä. Se on mitta tarkkuus näytteen keskiarvosta. Näytteen keskiarvo on tilastotieto, joka perustuu tietoihin, joilla on taustalla oleva jakautuminen. Emme voi visualisoida sitä samalla tavalla kuin tiedot, koska olemme suorittaneet yhden kokeilun ja niillä on vain yksi arvo. Tilastollinen teoria kertoo, että näyte tarkoittaa (suurelle "tarpeeksi" näytteelle ja muutama säännöllisyys) noin normaalisti jaettuna. Tämän normaalin jakauman keskihajonta on se, mitä kutsumme vakiovirheeksi.

Kun haluamme verrata tulosten keinoja kahden näytteen kokeesta hoitoa A vastaan hoitoa B, meidän on arvioitava, kuinka tarkasti olemme mitaneet keinot.
Oikeastaan olemme kiinnostuneita siitä, kuinka tarkasti olemme mitanneet näiden kahden keinon erot. Me kutsumme tätä toimenpidettä eroeron standardivirheeksi. Et voi olla yllättynyt oppiaksenne, että näytevalmisteen eron standardivirhe on välineen vakiovirheiden funktio:

 , missä n on datapisteiden määrä.
, missä n on datapisteiden määrä.
Huomaa, että standardivirhe riippuu kahdesta osasta: näytteen keskihajonnasta ja näytteen koosta n . Tämä tekee intuitiivisesta mielestä: sitä suurempi on näytteen standardipoikkeama, sitä epätarkempi voi olla arvioimme todellisesta keskiarvosta.
Myös suuri näytekoko, sitä enemmän tietoa meillä on väestöstä ja tarkemmin, voimme arvioida todellisen keskiarvon.
SE on merkki keskiarvon luotettavuudesta. Pieni SE on osoitus siitä, että näyte keskiarvo on tarkempi heijastus todellinen väestö keskiarvo. Suuremman otoskoko yleensä johtaa pienempään SE-arvoon (kun näytekoko ei suoraan vaikuta SD: hen).
Suurin osa tutkimustuloksista sisältää näytteen ottamisen väestöstä. Sitten teemme johtopäätöksiä väestöstä näistä näytteistä saaduista tuloksista.Jos otettiin toinen näyte, tulokset eivät todennäköisesti vastaa täsmälleen ensimmäistä näytettä. Jos luokitusominaisuuden keskiarvo oli 3,2 näytettä, se voi olla 3,4 samankokoisen toisen näytteen osalta. Jos saisimme äärettömän määrän näytteitä (yhtä suuria) väestömme joukosta, voimme näyttää havaitut keinot jakeluksi. Voisimme sitten laskea keskimäärin kaikki näytteenottomme. Tämä keskiarvo olisi sama kuin todellinen väestömäärä. Voimme myös laskea näytteen välineiden jakautumisen SD. Tämän näytemekanismin jakautumisnopeus on kunkin yksittäisen näytearvon SE.
Meillä on siis tärkein havainto: SE on väestön keskiarvo.
| Näyte | Tarkoittaa |
| 1st | 3.2 |
| 2nd | 3.4 |
| 3rd | 3.3 |
| 4th | 3.2 |
| 5th | 3.1 |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| Tarkoittaa | 3.3 |
| Std. Dev. | 0.13 |
Taulukko, joka kuvaa SD: n ja SE: n välistä suhdetta
Nyt on selvää, että jos tämän jakelun SD auttaa meitä ymmärtämään, kuinka paljon otoksen keskiarvo on todellisesta väestökehityksestä, voimme käyttää tätä ymmärtämään kuinka tarkka jokin yksittäinen näytearvo on suhteessa todellinen keskiarvo. Se on SE: n ydin.
Todellisuudessa olemme piirittäneet vain yhden näytteen väestöstämme, mutta voimme käyttää tätä tulosta arvioidaksemme havaitun näytearvon luotettavuutta.
Itse asiassa SE kertoo meille, että voimme olla 95% varma siitä, että havaittu näyte keskiarvo on plus tai miinus noin 2 (tosiasiallisesti 1,96) vakio virheet väestöstä keskiarvo.
Alla olevassa taulukossa esitetään vastausten jakautuminen tutkimuksessamme käytetystä ensimmäisestä (ja ainoasta) näytteestä. SE: n ollessa suhteellisen pieni 0,13 osoittaa, että keskiarvo on suhteellisen lähellä koko väestömme todellista keskiarvoa. Keskimääräinen virhevirhe (95%: n luottamus) on (noin) kaksinkertainen arvoon (+/- 0,26), kertoo meille, että todellinen keskiarvo on todennäköisesti välillä 2,94 ja 3,46.
| Vastaaja | luokitus |
| 3 | |
| B | 3 |
| C | 3 |
| D | 3 |
| E | 4 |
| F | 4 |
| G | 3 |
| H | 3 |
| minä | 3 |
| J | 3 |
| Tarkoittaa | 3.2 |
| Std. erehtyä | 0.13 |
Yhteenveto
Monet tutkijat eivät ymmärrä eroa standardipoikkeaman ja standardivirheen välillä, vaikka ne ovat yleisesti mukana tietojen analysoinnissa. Vaikka standardi poikkeama ja standardivirhe todelliset laskelmat näyttävät hyvin samalta, ne edustavat kahta hyvin erilaista, mutta toisiaan täydentäviä toimenpiteitä. SD kertoo jakelumuotomme, kuinka lähellä yksittäisiä tietoja on keskiarvosta. SE kertoo kuinka lähelle otostamme keskiarvo on koko väestön todellinen keskiarvo. Yhdessä he auttavat antamaan täydellisemmän kuvan kuin mitä yksin keskimääräinen voi kertoa meille.


